How Companies Build AI Platforms: Feature Stores, Pipelines, and Monitoring
Most companies do not fail at AI because they picked the “wrong model.” They fail because they treat AI like a one-off experiment instead of a production system that needs reliable data, repeatable delivery, and continuous control.
That gap is showing up in market data. While McKinsey reports that 71% of organizations regularly use generative AI in at least one business function, the transition to production remains brutal. Gartner predicts that at least 30% of generative AI projects will be abandoned after the Proof of Concept (PoC) phase by the end of 2025, citing issues like poor data quality, risk controls, cost, and unclear value.
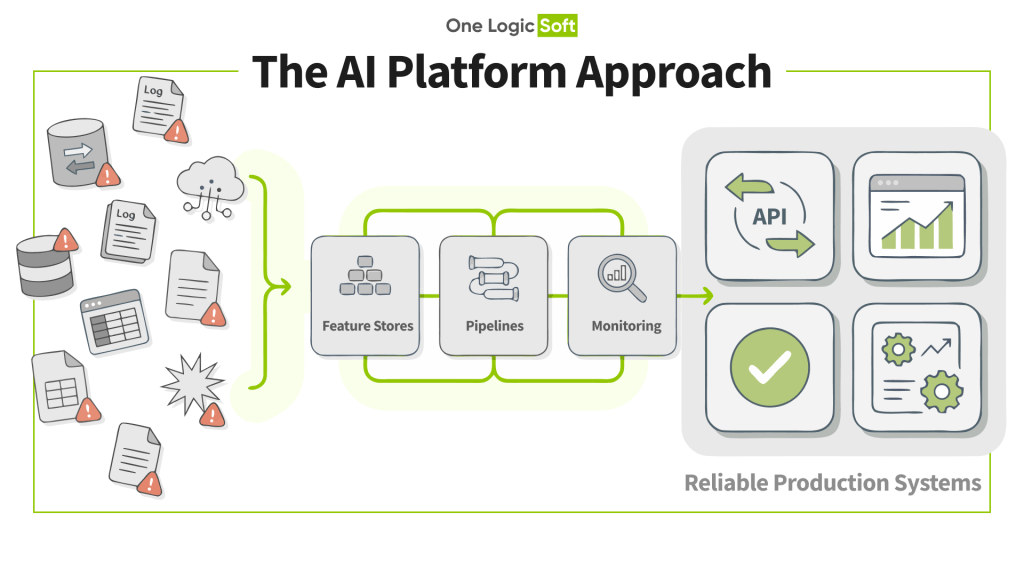
The practical response to this “PoC purgatory” is an AI platform approach: shared infrastructure that standardizes how features are created, how models are deployed, and how performance is monitored.
What “AI Platform” Means in Practice
An AI platform isn’t just a collection of tools; it is a set of reusable components that turns messy operational reality into stable, measurable capabilities. It typically consists of:
- Data Products: Consistent data signals across training and inference.
- Pipelines: Automation that makes delivery repeatable, testable, and auditable.
- Monitoring: Observability that detects silent degradation early and triggers action.
This article focuses on the three pillars that usually determine whether AI scales: feature stores, pipelines, and monitoring.
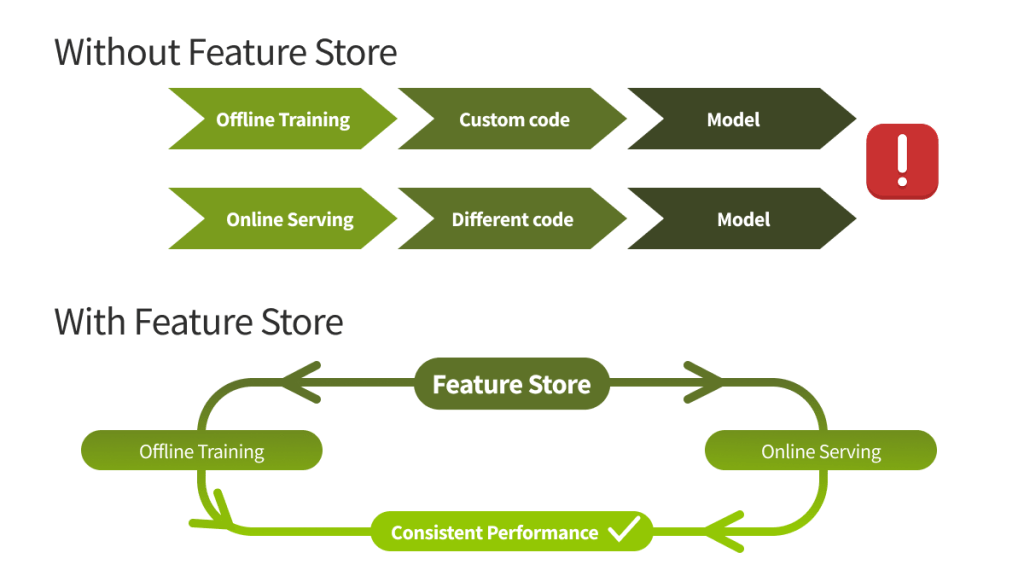
1. Feature Stores: Turning Raw Data into Reusable Signals
A feature store is an ML-specific data system that runs transformations, stores features, and serves them consistently for training and inference. Without it, teams often rewrite the same logic like “customer lifetime value” or “risk flags” in multiple places, leading to inconsistencies.
Why Companies Adopt Feature Stores
- Consistency (Solving Training-Serving Skew):
One of the fastest ways to fail is when a model looks great offline but fails in production because the data definitions differ. A feature store ensures the logic used to train the model is identical to the logic used during real-time inference. - Reuse and Speed:
When a feature is registered once, it becomes discoverable. A “churn risk” feature built for one model can be instantly reused by a marketing personalization model, reducing duplicate engineering. - Governance:
A mature feature store tracks ownership, freshness expectations, and dependencies. This is critical when upstream data changes and breaks downstream business metrics.
Key Design Decisions
- Point-in-time Correctness: Ensuring you don’t accidentally train on “future information” (leakage), which leads to overestimating model performance.
- Standardized Transformations: Defining transformations once to serve both batch training and online inference.
2. Pipelines: Moving from Artisanal to Repeatable Delivery
A pipeline is the automation that turns data and code changes into a tested artifact. It shifts the process from “a data scientist ran this on their laptop” to “the system built and verified this model.”
The Model Registry: The Source of Truth
Central to the pipeline is the Model Registry. This is where versions, lineage, and approvals live. It allows the business to answer critical questions:
- Which specific data and code produced the model currently in production?
- What performance metrics did it pass before release?
- What exactly changed between Version A and Version B?
Orchestration Choices
- Kubernetes-native (e.g., Kubeflow): Best for portability, scaling, and complex, consistent environments.
- Cloud-native Managed Pipelines: Best for faster adoption and lower maintenance overhead, assuming a specific cloud vendor alignment.
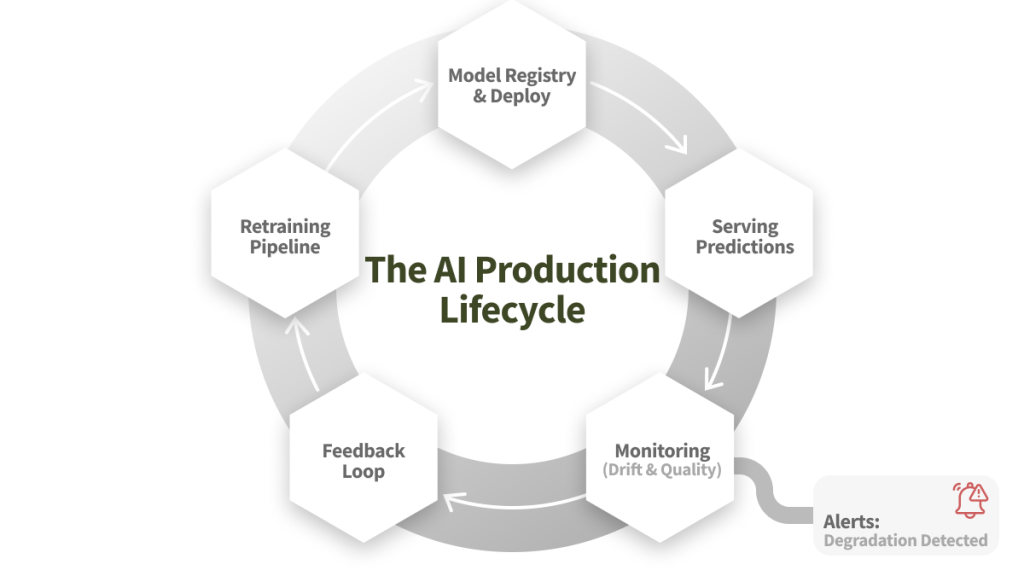
3. Monitoring: Preventing Silent Degradation
Monitoring is where “AI as a Product” becomes real. Unlike standard software, AI models degrade silently. The code doesn’t crash, but the answers get worse because the world has changed.
What to Monitor Beyond Uptime
| Metric Category | What to Watch For |
| Data Quality | Missing values, invalid ranges, schema changes, and broken joins. |
| Drift & Skew | Skew: Mismatch between training data and production data. Drift: The real-world data distribution changing over time. |
| Model Performance | Accuracy, precision/recall, and cost-weighted error (when feedback labels are available). |
| Operational Signals | Latency, timeouts, queue depth, and cost per 1k predictions. |
| Business KPIs | Conversion rates, fraud losses, or support handle time. |
The Cost of Ignoring Quality
If you do not measure data quality and drift, you will discover problems through customer complaints or revenue loss. Gartner estimates poor data quality costs organizations millions annually. AI amplifies this cost because models faithfully operationalize whatever bad data you feed them.
Reference Blueprint: Components and Responsibilities
Here is a practical blueprint teams use to scale AI across multiple use cases.
| Platform Layer | Primary Responsibility | Failure Modes to Prevent |
| Data Ingestion | Bring raw events and logs into a controlled zone. | Broken schemas, late data, silent null spikes. |
| Feature Store | Define, compute, store, and serve features consistently. | Training-serving skew, data leakage, stale features. |
| Training Pipeline | Train models repeatably with evaluation gates. | Non-reproducible runs, inflated offline metrics. |
| Model Registry | Versioning, lineage, approvals, and promotion. | Unknown provenance, “shadow updates” bypassing checks. |
| Serving | Ship models behind stable APIs with rollouts. | Latency regressions, painful rollbacks. |
| Monitoring | Detect drift, skew, and quality issues. | Silent degradation, alert fatigue. |
| Feedback Loop | Capture outcomes to retrain models. | Retraining on noise or failing to retrain when needed. |
Build vs. Buy: An Honest Framework
Companies rarely build a platform from scratch on day one. A sensible evolution path is:
- Start with Managed Monitoring and a Registry. This gives immediate control, traceability, and safer deployments without heavy infrastructure lift.
- Add a Feature Store. Do this when you have 2-3 models sharing similar signals. This is when the reuse pays back the engineering cost.
- Invest in Orchestration. Move to Kubernetes-native or complex orchestration when portability or compliance scale makes it necessary.
The Bottom Line: Tools do not replace ownership. High-performing teams define clear roles where data owners manage contracts, model owners manage performance thresholds, and platform owners ensure the infrastructure stays invisible and reliable. This governance is exactly what prevents the “PoC abandonment” statistics mentioned at the start.
About One Logic Soft
One Logic Soft is a software engineering company specializing in custom app development for logistics, retail and e-commerce, banking, automotive, and other high-load industries.
The company builds web and mobile solutions using Java, PHP, Golang, Node.js, React, React Native, Angular, Kotlin, Swift, and cloud infrastructure on AWS and Azure. This enables delivery of transactional systems, real-time operational tools, and AI-driven components.
Founded in 2018, One Logic Soft operates across Europe and the Americas with teams in Ukraine, Poland, Estonia, and distributed locations worldwide.
In logistics software development, the company has practical experience with freight calculation, route control, warehouse and inventory management, driver support systems, and cloud-based platforms.
One Logic Soft works across the full product lifecycle, from early research and Proof of Concept to MVP development and long-term delivery models, including Dedicated Teams and Time and Material engagements.
Have a project in mind?
Let's chat
Your request has been accepted!
In the near future, our manager will contact you.
Have a project to discuss?

Have a partnership in mind?
