Responsible AI in Healthcare Products: Practical Controls for Safety, Privacy, and Drift

Custom software development in healthcare increasingly includes AI features that influence triage, documentation, scheduling, and patient communication. The hard part is not proving that a model can work in a controlled test. The hard part is keeping it safe and predictable after release, when real-world inputs shift, workflows evolve, and people start relying on the output more than the team expected.
Responsible AI is not a separate policy layer. In practice, it is a set of product controls that make AI behavior bounded, auditable, and stable over time. This article focuses on three areas that decide whether an AI feature is production-ready in healthcare: safety, privacy, and drift.

What Responsible AI means in a healthcare product
In healthcare, “responsible” is not an abstract label. It means your product can explain what the AI is allowed to do, prove that it behaves that way, and show how you will detect and fix issues when reality changes. If you cannot answer these questions quickly during an incident, the system is not controlled.
A practical Responsible AI program should be able to answer, at any time:
· What is the intended use and what is explicitly out of scope?
· What data can the feature access, store, or transmit?
· When does the system abstain, escalate, or require human confirmation?
· How do we monitor for degradation, unexpected behavior, and privacy risk?
· What is the rollback and retraining process if things go wrong?
Safety controls
Safety is the ability to avoid harm in real clinical workflows. That means you design the feature as part of a human process, not as a stand-alone model. The controls below reduce the most common production failures: unclear scope, hidden data shifts, overreliance, and poor change control.
1) Lock down intended use and boundaries
Most “surprises” start with scope creep. Teams ship a feature for one setting, then users apply it elsewhere. Treat intended use as a versioned product artifact that changes only through review.
Your intended use definition should include:
· Clinical task, setting, and user role (who uses it and where in the workflow).
· Patient population and exclusions (who the feature is not designed for).
· Inputs and outputs (what data it reads, what it produces, what it never produces).
· Required user action (what a user must verify before acting).
· Out-of-scope conditions (devices, modalities, languages, edge scenarios).
Release rule: any change to intended use triggers revalidation, updated monitoring, and updated user-facing boundaries.
2) Data controls that prevent silent failure
Healthcare data pipelines create risk in subtle ways: duplicates across splits, proxy labels, post-outcome fields, site-specific artifacts, and annotation drift. Data controls are the earliest and cheapest safety controls.
Implement these controls before training:
· Provenance ledger (source, timeframe, approvals, access history).
· Patient-level split integrity and duplicate detection across datasets.
· Target leakage scans for post-outcome fields or proxies that will not exist in real use.
· Label QA (agreement checks, adjudication rules, audits on hard cases).
· Coverage mapping by site, device, protocol, and cohort to make gaps explicit.
3) Model acceptance gates tied to clinical reality
A single average metric can hide the failures that matter. Gate releases on the worst slices you can defend clinically, not only on overall accuracy.
A useful release gate combines:
· Slice-based thresholds (site, device, age bands, sex, acuity, language).
· Calibration checks so probability outputs match real-world meaning.
· Robustness tests for missing fields, noisy inputs, and low-quality data.
· Abstain behavior for insufficient evidence instead of guessing.
· Regression tests for known failure modes observed in testing or support tickets.
4) UX controls to reduce overreliance
Even a strong model becomes unsafe when users treat it as an authority. UI is part of safety engineering. The goal is to support fast decisions without turning the output into a default truth.
Practical UI controls include:
· Surface scope limits and uncertainty at the decision point, not in a PDF.
· Add confirmation steps for high-impact actions or irreversible changes.
· Show the small set of evidence signals users can verify quickly.
· Track overrides, disagreements, and alert fatigue as safety indicators, then act on them.
Privacy controls
Privacy in healthcare products fails through everyday tooling: logs, analytics events, screenshots, exports, vendor integrations, and support processes. If you want privacy controls that survive real operations, design for minimization, separation, and controlled access from day one.
1) Minimize data and enforce access discipline
If a field is not required for the feature to function, it should not be collected or stored. This principle reduces breach impact, audit burden, and accidental leakage.
Core controls:
· Data minimization tied to clear feature requirements.
· Role-based access with MFA and least privilege across environments.
· Just-in-time approvals for sensitive datasets, fully audited.
· Retention rules with verified deletion workflows, including backups where applicable.
2) Engineering controls that survive integrations
Most teams secure databases but forget the paths around them. Your goal is to keep sensitive content out of places that were never meant to be a PHI store.
Controls that pay off quickly:
· Encryption in transit, at rest, and in backups.
· Pseudonymization with key separation (re-identification keys stored separately with stricter controls).
· PHI-safe logging by default (no raw payloads in logs, traces, or analytics).
· Automated scanning for sensitive fields in telemetry and error reports.
· Strict egress controls for exports and vendor access, with explicit approvals.
3) Additional controls for LLM features
If you use LLMs for summarization, chat, or documentation assistance, you must control what enters the context and what leaves the system. LLM features often fail through over-sharing, tool misuse, or prompt injection.
Practical controls include:
· Context filters to reduce accidental inclusion of identifiers and unrelated notes.
· Output filters to prevent echoing sensitive content back to the user.
· Tool access restrictions (what the model can query, write, or send).
· Human review for high-impact outputs, such as clinical summaries used in official records.
Drift controls
Drift is a lifecycle problem. It is not enough to retrain occasionally. You need detection signals, action thresholds, and a release process that can respond without chaos.
Three drift types to track
Data drift happens when inputs shift, for example a new device, a new site, a new protocol, or a change in documentation style. Label drift happens when coding practices or guidelines change. Concept drift happens when the relationship between inputs and outcomes changes, for example after new treatments or workflow changes.
Monitoring signals that matter
Start with signals that are easy to measure and tightly linked to action. If you wait for perfect labels, you will detect problems too late.
Recommended signals:
· Schema, missingness, and range checks on inputs.
· Site and device mix shifts across time windows.
· Confidence trends and changes in abstain rates.
· User behavior signals: overrides, disagreements, alert fatigue.
· Delayed-label evaluation jobs when ground truth arrives later.
Response playbooks
Monitoring without response rules is noise. Define what happens when a threshold is crossed, who owns the decision, and how quickly you can contain impact.
Your playbook should include:
· Investigation thresholds and on-call ownership.
· Rollback triggers and a one-click revert path.
· Retraining rules with data QC, slice checks, and release gates.
· Post-incident review that ends with concrete engineering changes.
Control matrix
This matrix connects common production failures to the controls that prevent them and the signals that tell you when to act. Use it as a baseline and tighten it for your specific clinical workflow and risk profile.
| Risk area | Typical production failure | Controls to implement | What you monitor | What to do when triggered |
| Safety: scope | The feature is used outside intended settings, for example a different patient group or workflow step. | Intended use and out-of-scope list, UI guardrails, API validation, release review for scope changes. | Out-of-scope usage patterns, unusual user flows, support escalation volume. | Block or warn, update guardrails, revalidate if the scope is expanding. |
| Safety: data | New sites, devices, or protocols shift inputs and break assumptions. | Coverage mapping, drift checks, robustness tests, data QC gates. | Device and site mix shifts, missingness spikes, schema violations. | Investigate, shadow test updated preprocessing, retrain only with QC and gates. |
| Safety: performance | Performance drops on a subgroup that matters clinically. | Slice thresholds, calibration checks, regression suite, abstain logic. | Slice metrics, confidence shifts, override spikes, complaint clusters. | Roll back if impact is high, then fix with targeted data and validation. |
| Human factors | Overreliance, alert fatigue, or poor escalation behavior. | Uncertainty display, friction for high-risk actions, escalation rules, training mode. | Acceptance rate, override rate, time-to-action, escalation patterns. | Adjust UX and thresholds, refine escalation logic, retrain user workflows if needed. |
| Privacy | Sensitive data leaks through logs, analytics, exports, or vendors. | Redacted logging, key separation, egress controls, access audits, vendor restrictions. | Sensitive field detectors, unusual exports, access anomalies. | Contain, rotate keys if needed, audit access, patch pipelines, notify stakeholders per policy. |
| Drift | The feature degrades over time without obvious errors. | Input monitoring, delayed evaluation, retraining cadence, controlled releases. | Drift scores, confidence trends, proxy metrics, delayed label reports. | Investigate, shadow deploy a new model, roll back if user impact grows. |
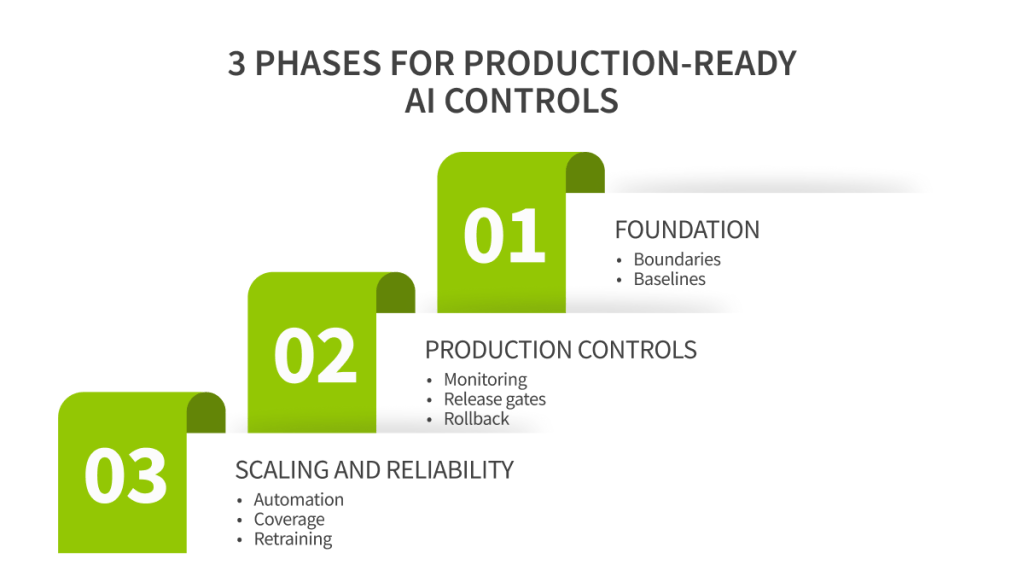
Implementation plan
Responsible AI becomes real when it shows up in backlog items, release criteria, and runbooks. The path below is a practical way to build the control layer without freezing product delivery.
Phase 1: Foundation
Define scope, data responsibilities, and the baseline measurement plan. Do not wait for a perfect model. Start with controllable behavior and traceability.
· Intended use and out-of-scope definition, versioned and reviewable.
· Data provenance, labeling QA rules, and dataset coverage mapping.
· Baseline evaluation and slice plan, including calibration checks.
· Audit logging design that avoids storing PHI in general logs.
Phase 2: Production controls
Ship the feature with monitoring and containment built in. If monitoring is postponed, drift becomes an incident.
· Release gates and regression suite that can block unsafe updates.
· Monitoring dashboards, alert thresholds, and ownership of responses.
· Rollback path tested in staging and rehearsed operationally.
· Human escalation routes and UI guardrails for high-risk decisions.
Phase 3: Scaling and reliability
Once the control layer works, scale coverage and automation. This is where teams reduce long-term operational cost.
· Automated evaluation pipelines that run on a schedule and per release.
· Cohort coverage improvements through targeted data collection.
· Retraining cadence with QC gates and slice-based acceptance.
· Ongoing human factors testing and UX adjustments based on real behavior.
If you are shipping an AI feature in a healthcare product and want it to remain safe, private, and stable after launch, you need more than model tuning. You need a control layer that is integrated into architecture, pipelines, and operations. Custom software development services can package that work into a clear delivery program: boundaries, monitoring, release gates, incident response, and retraining workflows that fit your product roadmap.
If you share four details, the control set above can be converted into a concrete plan and checklist tailored to your feature:
· Feature type (triage, summarization, prediction, detection).
· Inputs (EHR fields, text notes, images, signals).
· Users (clinicians, nurses, ops teams, patients).
· Deployment setting (sites, devices, regions).
FAQ
What is the fastest way to reduce risk before launch?
Lock scope first, then add slice-based acceptance gates, monitoring, and a tested rollback path. Most serious incidents come from unclear boundaries and uncontrolled change, not from small metric gaps.
How do we manage drift when labels arrive weeks later?
Use leading indicators immediately, input drift, overrides, disagreement rates, confidence trends, and abstain rate changes. Then run delayed evaluation jobs on labeled windows and connect thresholds to actions such as investigation, shadow deployment, retraining, or rollback.
Do we need different controls for LLMs vs predictive models?
Yes. LLM features need extra controls around what enters context, what the model can access via tools, and what it can output. Predictive models rely more on slice validation, calibration, robustness testing, and stable preprocessing across sites and devices.
What should we log to debug incidents without leaking PHI?
Log versions, metadata, and decision traces with redaction by default. Keep raw identifiers out of standard logs. If deeper traces are required for safety review, store them in restricted systems with strict access audits and retention rules.
How do we prevent scope creep over time?
Treat intended use as a versioned artifact enforced in UI and APIs. Tie scope changes to release reviews and revalidation. If the feature is expanding to new populations or workflows, plan it as a new release, not an informal extension.
Have a project in mind?
Let's chat
Your request has been accepted!
In the near future, our manager will contact you.
Have a project to discuss?

Have a partnership in mind?
