AI Observability 2.0: From Incident Detection to Root Cause Prediction
Artificial intelligence is changing how companies maintain the stability of their systems. For many years, engineers relied on traditional monitoring tools that answered a single question: Is something broken right now?
As digital infrastructure grew more complex and interconnected, this question stopped being enough. The real challenge became understanding why something broke and what is likely to fail next.
Modern organizations generate millions of data points every second. Logs, traces, metrics, GPU loads, and model signals pour into dashboards faster than humans can interpret them. The task is no longer to detect incidents but to predict them before they occur. That goal defines the new discipline called AI Observability 2.0.
From observation to anticipation
AI observability combines classical monitoring with machine learning to find meaning inside enormous volumes of telemetry. Instead of using fixed thresholds, such systems learn what normal behavior looks like for every model, dataset, and service. When that behavior begins to change, the system highlights it, explains possible reasons, and can even react automatically.
In practice, AI observability creates a living view of the digital environment. It does not simply report errors. It connects events across services and shows how one minor anomaly can cause a larger incident later. A delay in one API may result from data drift, an overloaded processor, or a problem in a neighboring microservice. By connecting these elements, engineers move from firefighting to prevention.
Why it matters now
Downtime is more expensive than ever. Independent studies by New Relic and Technavio estimate that the market for AI observability will exceed 2.9 billion dollars by 2029 as companies seek to control complex cloud and AI workloads. Every minute of service disruption can cost a business hundreds of thousands of dollars. Even more damaging are silent failures, when an AI model continues to operate but produces inaccurate results. These errors are invisible at first yet create long term financial and compliance risks.
Observability now functions as the nervous system of modern infrastructure. It connects operations, data science, and governance into one framework that explains how system performance influences business results.
How AI Observability 2.0 works
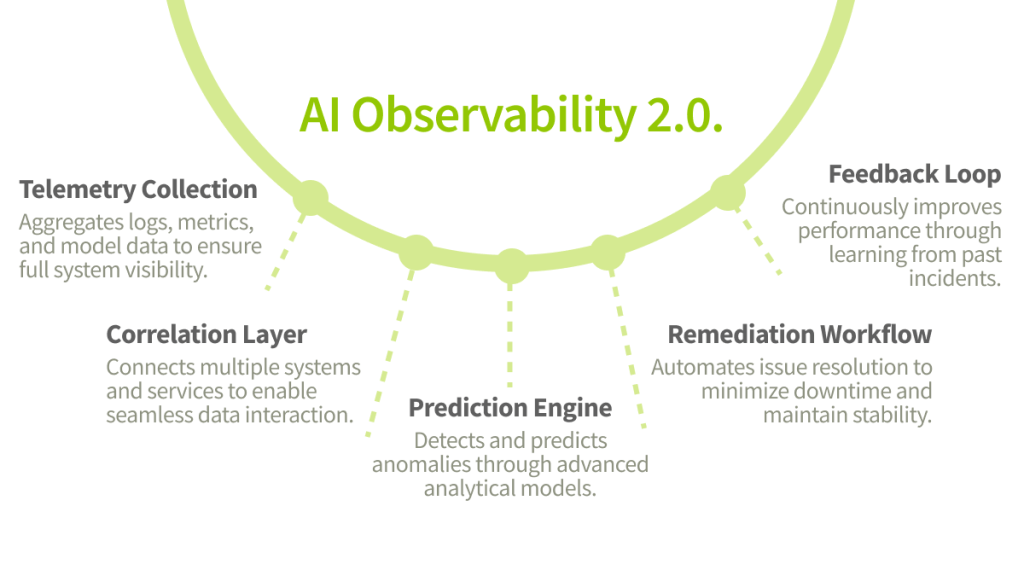
The process begins with the collection of telemetry from every layer of the stack. Logs, traces, and metrics are gathered together with data from machine learning models. Analytical engines study this information and identify relationships that may not be visible to humans. When the system detects patterns that resemble earlier incidents or statistically unusual behavior, it generates an alert that already includes context and explanation.
The next stage is remediation. Intelligent observability can trigger an automatic rollback, increase computing resources, or switch to a safer model version. Engineers stay in charge but the system gives them insight faster than any manual investigation could.
Comparative overview
| Traditional Monitoring | AI Observability 2.0 |
| Uses static thresholds and manual alerts | Applies adaptive machine learning for anomaly detection |
| Focuses on visible symptoms | Analyzes causes and dependencies |
| Correlation handled manually | Correlation handled automatically across systems |
| Responds after a failure occurs | Predicts and prevents failures before they happen |
| Works mainly with infrastructure data | Includes data drift, model performance, and business metrics |
| Manual recovery procedures | Automated or guided recovery workflows |
This change does not replace human knowledge. It enhances it by providing richer context and faster access to insights that were previously hidden.
Business value and organizational impact
Companies that have implemented AI observability report faster incident resolution, fewer false alarms, and better cooperation between development and data teams. The technology turns fragmented information into a unified operational language. Data scientists understand how infrastructure influences model performance, and DevOps teams see how model behavior affects uptime.
Beyond reliability, observability also improves compliance. The European AI Act, for example, requires traceability and accountability in automated systems. Observability provides continuous logs, data lineage, and model version history, turning what used to be a compliance burden into an advantage.
For industries such as logistics and retail, where One Logic Soft focuses its projects, observability directly saves money. Predictive maintenance of digital systems prevents service interruptions in supply chain platforms and customer analytics tools. Problems are identified before users or clients experience them.
Implementation mindset
The most successful teams include observability from the very beginning of development. They start with mapping critical services and setting up basic telemetry, then gradually expand into predictive models and automated recovery. The best approach is to begin with one essential process or application, prove its value, and extend the system step by step. Over time, observability becomes part of the company’s engineering culture rather than a separate technical task.
Common challenges and solutions
The first obstacle is the volume of data. Millions of events per hour can overwhelm storage and analysis tools. Intelligent filtering and prioritization are needed to focus on meaningful signals. Another difficulty is lack of context. Alerts that appear isolated are difficult to act on. This is solved through dependency mapping and correlation analysis that show how components influence one another.
The human factor also matters. Observability touches several departments at once. It requires coordination between software engineers, data scientists, and security specialists. Clear ownership and shared metrics help teams build trust in the process and achieve consistent improvement.
The OneLogicSoft perspective
For clients of OneLogicSoft, observability is not an optional service. It is built directly into the development of AI and cloud systems. Each project includes continuous telemetry, model tracking, and automated diagnostics. The goal is to create infrastructure that learns from its own operation, detects early signs of risk, and adapts before users notice a problem.
This approach unites predictive analytics, DevOps, and compliance into one consistent framework that scales with the client’s business.
Frequently Asked Questions
What makes AI observability different from monitoring?
Monitoring reports whether a service is running. Observability analyzes the reasons behind its behavior and predicts possible issues using advanced analytics and machine learning.
Can it really predict failures?
Yes. By studying past incidents and performance data, AI observability identifies early warning signs such as latency spikes or abnormal resource use that usually precede outages.
Is it only suitable for large corporations?
No. Even small companies can gain value, especially if they rely on several cloud services or machine learning models. Most modern platforms scale easily from one application to many.
How does it help with compliance and audits?
It records every version of models, datasets, and configurations. This creates a clear audit trail that supports transparency and accountability as required by the European AI Act.
What tools are typically used?
Examples include Grafana, Datadog, New Relic, Monte Carlo Data, and LuciQ. They connect directly to cloud infrastructure and CI/CD pipelines through standard APIs.
Is complete automation possible?
Total autonomy is rare. The best systems combine automation with human oversight. The AI engine recommends actions while engineers confirm them.
Closing Thought
AI Observability 2.0 transforms operational visibility into foresight. It turns endless data streams into actionable intelligence, helping teams anticipate failures before they occur. In a world where artificial intelligence powers critical infrastructure, the ability to understand, predict, and continuously improve system behavior becomes the cornerstone of reliability and trust.
For companies developing digital products with OneLogicSoft, observability is not a tool, it’s a philosophy woven into every discipline, from QA in Product Development and Logistics Software Development to Project Planning. By embedding AI-driven observability across these stages, organizations gain systems that learn, self-optimize, and evolve in real time.
This is not merely a technical upgrade. It is the foundation of sustainable, intelligent operations where performance, resilience, and innovation advance together through the power of predictive insight.
Have a project in mind?
Let's chat
Your request has been accepted!
In the near future, our manager will contact you.
Have a project to discuss?

Have a partnership in mind?
