Claims Automation With AI: From Document Intake to Decision Support and Exceptions

Claims teams rarely lose time on complex judgment calls. Most delays come from repetitive work: reading inconsistent documents, chasing missing details, copying data between systems, applying the same policy logic again and again, and answering predictable customer questions. AI delivers value in claims only when it is designed as a workflow system first and a model second.
This article breaks claims automation into three practical layers:
- Document intake and data normalization
- Decision support that improves speed and consistency
- Exception handling that keeps risk controlled and outcomes defensible
What claims automation actually means in 2026
Most insurers already use some form of automation: web forms, rule engines, templates, RPA scripts, or call center macros. AI-driven claims automation goes further by handling unstructured inputs such as emails, PDFs, photos, letters, repair estimates, or medical reports and turning them into a clean, traceable workflow result.
In practice, mature claims automation typically includes:
- Multi-channel intake through portals, email, chat, phone transcripts, and partner feeds
- Intelligent document processing for classification, extraction, and validation
- Triage based on routing rules, severity, fraud signals, and SLA priorities
- Decision support for coverage checks, reserve suggestions, and next best actions
- Assisted communication for letters, information requests, and status updates
- Payments, subrogation triggers, and audit-ready logging
A reference architecture from intake to outcome
A reliable claims AI setup behaves like a pipeline with controlled decision gates.
Intake layer
Inputs arrive through portals, emails, broker systems, EDI feeds, call transcripts, or mobile photos.
Document processing layer
Documents are classified by type and key entities are extracted, such as policy numbers, dates, amounts, and claimant details. All fields are normalized into a structured schema.
Validation and enrichment
Extracted data is checked against policy administration systems and claims history. Coverage dates, deductibles, endorsements, prior losses, vendor rates, and basic fraud indicators are validated. Low-confidence fields are flagged.
Orchestration and decision engine
Rules and ML signals determine the next step: straight-through processing, adjuster review, specialist referral, or escalation.
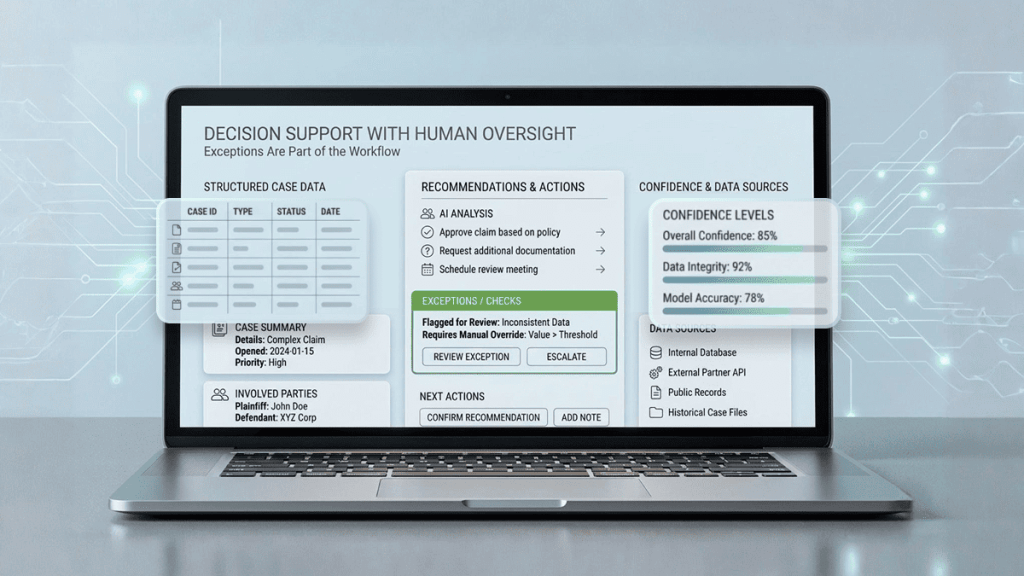
Decision support workspace
Adjusters receive a concise case brief with extracted data, evidence links, confidence scores, and clear reasoning behind each recommendation.
Outcome and audit trail
Every model output, rule execution, and human override is logged to ensure decisions remain explainable after the fact.
Where AI delivers the most value
1) Document intake and normalization
Claims data is inherently inconsistent. AI becomes useful when it converts that inconsistency into a validated, structured record.
Common automations include:
- Splitting and classifying multi-document files
- Field extraction with direct evidence references
- Duplicate detection across uploads
- Missing information detection
- Basic quality and consistency checks
This layer often produces the fastest return, because it reduces manual handling across nearly every claim.
2) Decision support for adjusters
Decision support is not about fully automated approvals or denials. Its role is to reduce variability, shorten handling time, and prevent rework while leaving room for human judgment.
Typical use cases include:
- Highlighting relevant policy clauses and prior similar cases
- Suggesting reserves based on loss type, region, and history
- Recommending next actions such as inspections or information requests
- Surfacing anomaly and fraud signals for review
The key principle is assistive, not autonomous, decision-making.
3) Exception handling as a core design element
Many automation initiatives fail because exceptions are treated as edge cases. In reality, exceptions define whether automation scales safely.
Poor exception handling leads to either excessive manual fallback or overly rigid automation that increases complaints and leakage.
Exceptions should be explicit workflow states. Common categories include:
- Low-confidence data extraction
- Coverage mismatches or inactive policies
- High-severity or high-value claims
- Dispute or escalation signals
- Fraud indicators
- Jurisdiction-specific requirements
Every escalation should answer two questions:
- Why was this claim flagged?
- What is the minimum human action needed to resolve it?
Implementation blueprint
A phased rollout usually works best.
Phase 1: Structured intake
Centralize inbound channels, deploy document classification and extraction, validate against core systems, and add confidence scoring with evidence links.
Phase 2: Triage and routing
Introduce severity scoring, SLA routing, assignment rules, and a standardized case brief for adjusters.
Phase 3: Decision support and automation gates
Add recommendations with explanations, enable straight-through processing for low-risk claims, and enforce human review for boundary cases.
Phase 4: Governance and exception operations
Implement monitoring for drift, maintain documentation and audit exports, and define transparency and oversight workflows.
Metrics that actually matter
Focus on operational outcomes rather than model-level metrics:
- Cycle time, including tail latency
- Human touch time per claim
- Straight-through processing rate with strict definitions
- Reopen and supplement rates
- Override frequency and patterns
- Complaint rate relative to claim volume
- Model stability and error clustering
Mapping the workflow to AI capabilities and controls
| Claims stage | AI capability | Output | Key control points |
| Intake | Classification, deduplication | Claim record created | Channel validation, security checks |
| Extraction | OCR and ML extraction | Structured fields with evidence | Confidence thresholds, review triggers |
| Validation | Rules and entity resolution | Clean record | Cross-system checks |
| Triage | Scoring models and rules | Routing and priority | Bias checks, override logging |
| Decision support | Retrieval and summarization | Recommended actions | Explainability, human oversight |
| Settlement | Rules and assisted drafting | Payment proposals | Approval limits, jurisdiction rules |
| Exceptions | Pattern detection | Escalation tasks | Specialist routing, audit logs |
Common pitfalls to avoid
- Treating AI as a single tool instead of a coordinated workflow
- Omitting evidence links for extracted data
- Automating high-risk claims too early
- Relying solely on brittle RPA scripts
- Launching without a governance and monitoring plan
FAQ
Can claims be fully automated end to end?
Only for a narrow set of low-risk claims with strict thresholds. Most value comes from structured intake, triage, and decision support.
What data is needed to start?
A curated set of historical claim packets with documents and outcomes is usually sufficient for early phases.
How do we keep decisions defensible?
By logging extracted data with evidence, confidence scores, model versions, rule outputs, and all human overrides.
How should model drift be handled?
Monitor input distributions, confidence trends, error clusters, and complaint signals, and treat drift as an operational issue with clear ownership.
What is a realistic first milestone?
A clean structured record, reliable routing, and a usable case brief for one or two claim types.
How One Logic Soft approaches claims automation
At One Logic Soft, we work with claims automation as a system design problem, not as a model deployment task. The focus is on workflows that stay understandable under audit, predictable in edge cases, and practical for adjusters and operations teams.
We typically help teams assess where automation creates real leverage, how data should move across intake, decision support, and exceptions, and what needs to be in place before scaling AI-driven decisions.
If you are evaluating claims automation or want to sanity-check an existing setup, we can review your current workflow and outline what is realistically achievable, where the risks sit, and what a phased rollout would look like.
Have a project in mind?
Let's chat
Your request has been accepted!
In the near future, our manager will contact you.
Have a project to discuss?

Have a partnership in mind?
