Retail Data Strategy for 2026: Unifying Identity and Product Data for AI
Retailers already collect huge volumes of data. In 2026, the competitive gap comes from something simpler: whether your data is connected and consistent enough for AI to act on it safely.
Most AI initiatives in retail break for one of three reasons:
- Customer identity is fragmented across channels.
- Events mean different things in different systems.
- Product data is inconsistent at the SKU and variant level.
When those three are unified, AI becomes practical across the full retail stack: personalization, search, recommendations, demand forecasting, inventory planning, returns, fraud detection, customer support, and retail media measurement.
The 2026 goal in one sentence
Build one identity layer, one event language, and one product truth layer, then treat them as shared infrastructure for every AI use case.
Why unification matters more in 2026 than it did in 2024
AI systems are now fast enough to amplify both your best signals and your worst data problems. In earlier years, messy data mostly produced messy dashboards. In 2026, messy data produces messy automated decisions at scale: wrong recommendations, wasted retail media spend, broken attribution, misleading forecasts, and operational noise.
Unification is also no longer just a marketing project. It is operational infrastructure. It affects merchandising, supply chain, store operations, contact centers, and finance.
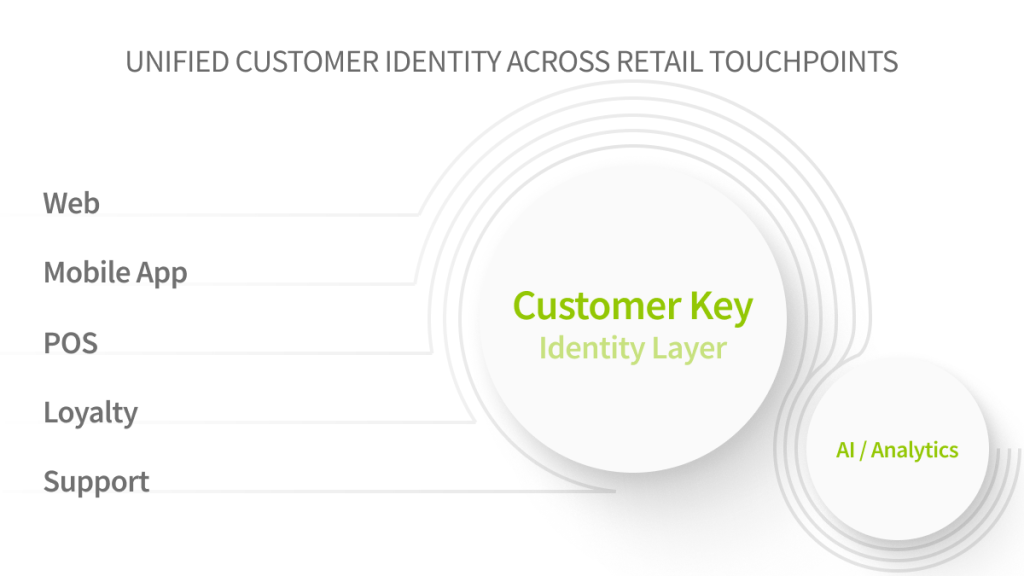
Pillar 1: Identity data
What “unified identity” actually means
Unified identity is not a single CRM record. It is a graph of relationships that connects shoppers across:
- Website and mobile app sessions
- Loyalty and email activity
- POS transactions and returns
- Customer support interactions
- Household context where permitted
- Marketing and retail media touchpoints where permitted
The output you want is a stable customer key that downstream systems can reference consistently.
What to build first
A workable identity layer typically includes:
- Deterministic matching rules (loyalty ID, verified email, phone) as the primary method
- Probabilistic linking as a secondary method, always with confidence scoring
- Consent and purpose tracking attached to identity links
- A clear split between restricted PII storage and activation-ready tokens or hashes
Common identity mistakes that derail AI
- Treating identity as “solved” once the CDP is deployed
- Letting every tool create its own customer ID without a shared key
- Ignoring match confidence, which leads to over-personalization and incorrect measurement
- Mixing consent rules into business logic instead of enforcing them as part of identity data
Pillar 2: Event data
Why event data is the most underestimated problem
Retail systems generate events everywhere, but definitions vary:
- “Purchase” differs across e-commerce, POS, and subscriptions
- Returns arrive later and rewrite the margin story
- Promotions are often disconnected from product variants
- Inventory status can lag behind demand events
AI needs consistent event meaning more than it needs more events.
Build an event language
A strong event foundation has:
- A canonical schema for core events (view, search, add-to-cart, purchase, return, price change, promo exposure, stock change, shipment, support ticket created)
- A shared identity key and shared product key on every relevant event
- Context that prevents bad inferences: channel, store, device, fulfillment mode, campaign, currency, discount type, timestamps, location granularity
Real-time vs near-real-time, choose deliberately
Not everything must be real-time. Split workloads by impact:
- Real-time: fraud signals, stock anomalies, personalization triggers, operational exceptions
- Near-real-time: forecasting refresh, segmentation updates, planning, reporting
This reduces cost and complexity while keeping the outcomes that truly need speed.
Data quality controls for event streams
At minimum, enforce:
- Schema validation and versioning
- Dedupe rules
- Late-arriving event handling (especially returns and cancellations)
- Reconciliation checks between transactional sources and analytics outputs
Pillar 3: Product data
Product data is your AI vocabulary
If identity answers “who” and events answer “what happened,” product data answers “what is this item, exactly.”
In retail, many AI features are product-led:
- Search ranking and relevance
- Recommendations and bundling
- Pricing and promotion optimization
- Retail media targeting and reporting
- Returns reduction and substitution logic
If the product truth layer is inconsistent, AI becomes unreliable even with perfect models.
What “product truth” should include in 2026
A practical product truth layer usually covers:
- Taxonomy and category rules
- Variant relationships (parent SKU, size, color, pack, bundle)
- Attribute completeness and controlled vocabularies
- Availability by region, channel, and fulfillment mode
- Lifecycle status (active, seasonal, discontinued, replaced-by)
- Content readiness (titles, bullets, images, manuals, compliance flags)
Product data problems that cause expensive AI failures
- Duplicate SKUs and broken variant mapping
- Attributes stored as free text without validation
- Missing lifecycle states, leading to promotion of discontinued items
- Out-of-stock logic inconsistent across channels
- Media and content assets not tied cleanly to variants
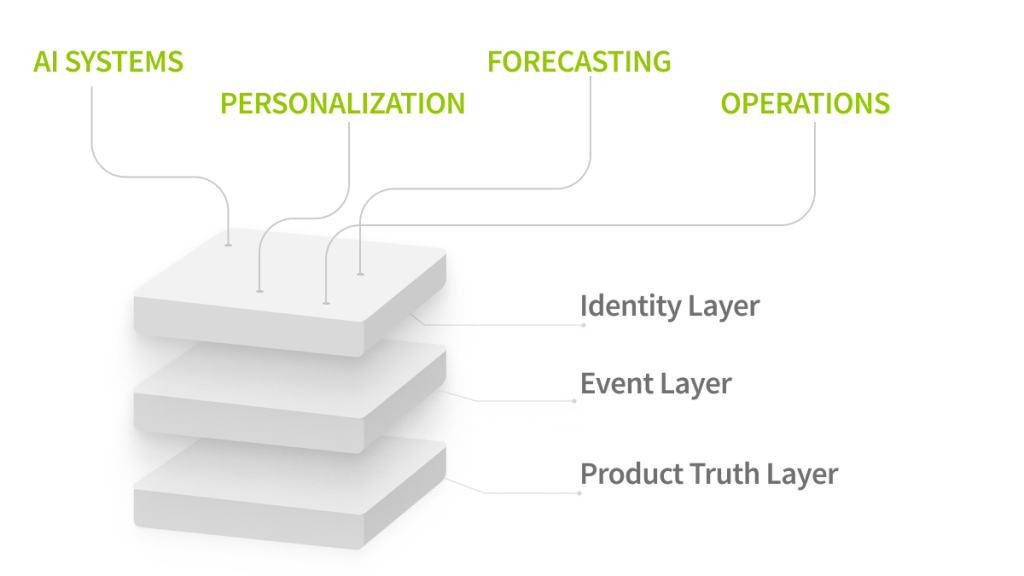
The unified spine: how identity, events, and product data connect
The unified retail spine is simple:
- Identity layer publishes a stable customer key and confidence signals
- Product truth publishes a stable product key and a consistent variant model
- Event layer uses both keys and a shared event schema to create a reliable timeline
Once you have this, downstream AI systems stop doing guesswork.
Table: What breaks AI first, and what to fix
| Data domain | Typical failure | Minimum checks | Breaks first in |
| Identity | duplicates, incorrect merges, consent gaps | match confidence, key stability, consent coverage, PII separation | personalization, attribution, retail media reporting |
| Events | inconsistent definitions, missing context, late updates | schema validation, dedupe, timestamp rules, reconciliation with sources | recommendations, forecasting, fraud, automation workflows |
| Product | messy attributes, variant confusion, bad lifecycle status | taxonomy rules, attribute completeness, variant mapping accuracy, availability sync | search, recsys, retail media optimization, pricing |
A vendor-neutral architecture pattern
You do not need one giant platform. You need clear responsibilities:
- Data collection connectors (web, app, POS, ERP/WMS, support, marketing)
- Raw storage (immutable logs and snapshots)
- Identity service (matching, confidence, consent, stable keys)
- Product truth service (taxonomy, variants, attribute governance, publishing)
- Event standardization (canonical schema, enrichment, dedupe, late events)
- Activation and analytics (personalization, search, recsys, BI, experimentation)
This design lets you modernize gradually without breaking existing reporting and operations.
Implementation roadmap
Phase 1: Define shared keys and contracts (2-6 weeks)
- Choose identity key strategy and confidence scoring
- Define product keys and variant model
- Define canonical schema for top events
- Establish consent, retention, and access policies
Phase 2: Build the spine and connect priority systems (6-12 weeks)
- Connect e-commerce, POS, PIM, loyalty, and support
- Produce standardized events in parallel with existing pipelines
- Publish product truth to downstream tools
- Start using identity keys consistently across activation and analytics
Phase 3: Activate AI with measurable outcomes (3-6 months)
Pick 2-3 use cases tied to business impact, for example:
- Search and recommendations that reduce zero-result searches and lift conversion
- Returns and fraud anomaly detection that reduces operational loss
- Inventory and demand models that reduce out-of-stocks and overstock
Then harden with monitoring: data drift, schema changes, and model performance.
What to measure so the program stays real
Track operational data quality and business results in the same dashboard:
- Identity: match rate by channel, confidence distribution, consent-compliant coverage
- Events: schema compliance, late event rate, dedupe rate, reconciliation accuracy
- Product: attribute completeness by category, variant mapping accuracy, availability correctness
- Outcomes: conversion lift, AOV impact, return rate change, forecast error reduction, media efficiency improvements
FAQ
Do we need a CDP first?
Not necessarily. A CDP can be useful for activation, but without stable identity keys, consistent event definitions, and clean product data, it mostly scales existing inconsistencies. In practice, teams get better results by defining the data spine first and then connecting CDP capabilities to well-structured inputs.
Is real-time data required for every AI use case?
No. Real-time data is essential only where it directly affects immediate decisions, such as fraud prevention, stock alerts, or trigger-based personalization. Forecasting, planning, analytics, and most reporting workflows perform just as well with near-real-time updates and are far easier to operate.
What is the fastest first win after unification?
Search and recommendations typically show improvements first once product attributes and event meanings are consistent. Operational use cases often follow quickly, especially stock anomaly detection, returns analysis, and promotion performance tracking.
What is the hardest part in practice?
Product data governance. Identity resolution and event pipelines can be built with engineering effort. Product truth requires ongoing agreement across merchandising, marketing, operations, and data teams on taxonomy, attributes, and lifecycle rules.
How do we handle privacy and consent without slowing everything down?
Treat consent as part of the data model. Store consent scope and purpose alongside identity links, enforce access rules at the identity layer, and expose only permitted data to downstream systems. This keeps compliance explicit and predictable instead of embedded in scattered business logic.
Closing
Reliable retail AI does not start with models. It starts with shared meaning.
When identity, events, and product data are unified into a single operational spine, AI systems stop compensating for ambiguity and begin producing results teams can trust. Personalization becomes measurable, forecasts become actionable, and automation stops creating downstream clean-up work.
As Custom Software Developers, One Logic Soft works with retail teams to design and implement this foundation step by step, fitting it into existing platforms and day-to-day operations. When AI initiatives stall because data is fragmented or inconsistent, progress usually comes not from adding another tool, but from putting a clear, shared data structure in place that everything else can depend on.
Have a project in mind?
Let's chat
Your request has been accepted!
In the near future, our manager will contact you.
Have a project to discuss?

Have a partnership in mind?
