Designing AI-Ready Architectures: What to Change Before Adding ML
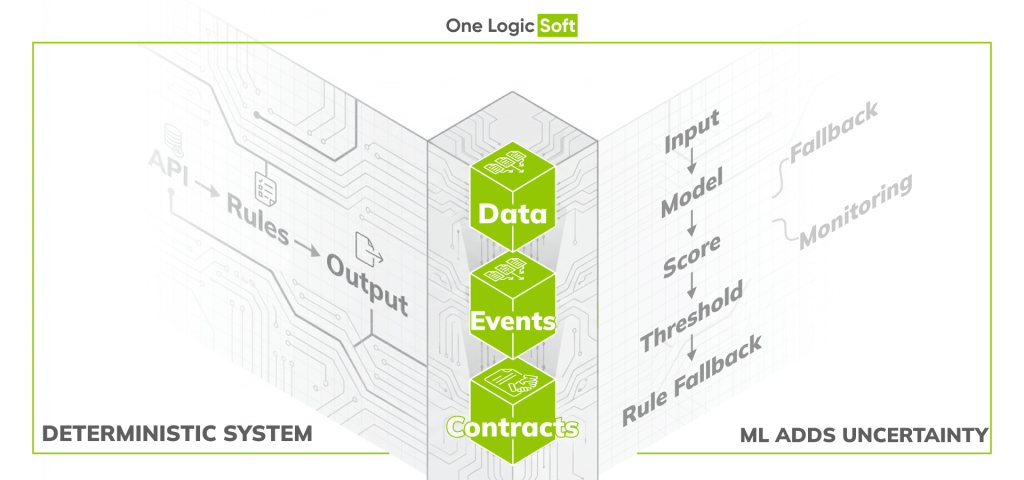
Why architecture needs to change before ML
Most ML initiatives fail for a predictable reason: the system was built for deterministic workflows, but ML introduces probabilistic decisions, new dependencies on data quality, and new operational failure modes. If the platform cannot track outcomes, reproduce features, and degrade safely when inference is slow or wrong, the “model” becomes a support burden instead of a product capability.
This is especially visible in Retail Software Development, where decisions like recommendations, demand signals, or fraud scoring must work under real latency, real data gaps, and fast-changing catalogs.
Define the decision contract before you model anything

An AI-ready architecture starts with a one-page contract that engineering, product, and stakeholders can all sign off on.
What the contract must include
- Input contract: required fields, sources, update frequency, allowed missingness
- Output contract: class, score, ranking, or text plus required metadata (confidence, explanation flags, version)
- Decision boundary: when the system trusts the model, when it falls back to rules, and when it routes to humans
- Success metric: an online metric tied to business outcomes, not only offline accuracy
- Failure behavior: what happens on timeout, partial inputs, or low confidence
If this contract is unclear, the training set, evaluation, and integration will all drift in different directions.
Fix identity and data semantics first
ML magnifies every inconsistency in your data model. The quickest way to sabotage a promising model is fragmented identifiers.
Identity fixes that pay off immediately
- Canonical IDs for customer, account, product, order, device, ticket
- Merge and mapping rules for legacy IDs and duplicates
- Session and attribution rules that are stable and auditable
- Deletion and retention logic that also applies to derived datasets and labels
The goal is simple: you can reconstruct “what happened” for any entity over time without guessing.
Build event data that is useful for ML, not just logs
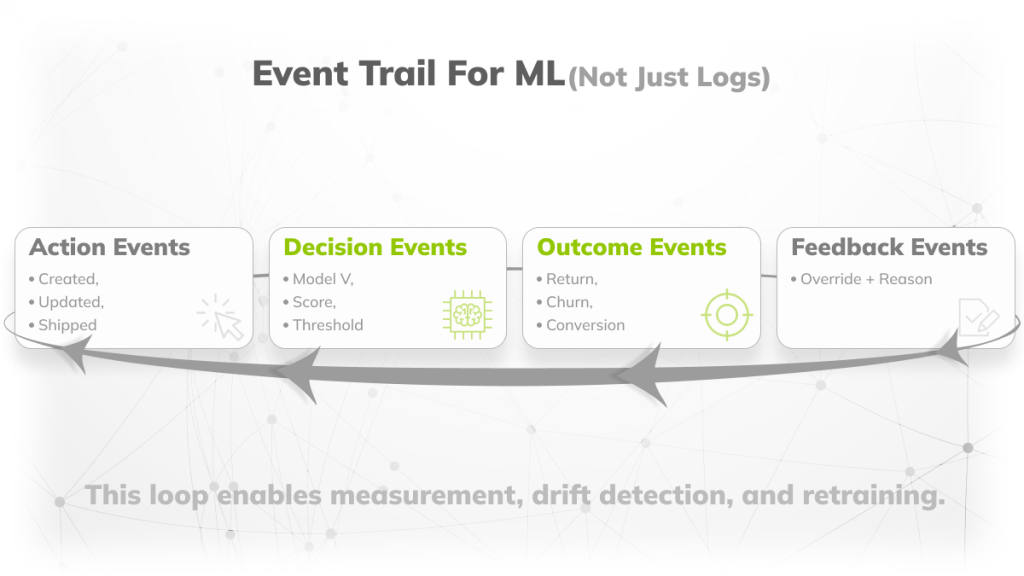
Traditional logs help developers debug. ML needs a structured event trail that supports reproducibility, labeling, and drift monitoring.
Events you should capture as first-class data
- Action events: created, updated, approved, refunded, shipped, escalated
- Decision events: model version, input snapshot hash, output, confidence, threshold used
- Outcome events: resolution, return, churn, conversion, dispute, rework
- Override events: human corrections and the reason category
Without these, you cannot measure real performance or build a reliable retraining loop.
Turn operational data into training data
Most companies have data, but not training-grade data. AI-readiness means the system can produce reproducible datasets and labels.
What to change in the architecture
- Add immutable event streams for key business actions
- Store timestamps and source metadata so features can be rebuilt historically
- Create explicit labels tied to outcomes, not inferred from random fields
- Support backfills so you can rebuild datasets without rewriting business logic
This is where many teams should pause and implement instrumentation first, especially in Logistics Software Development, where incomplete scans, delayed updates, and multi-system handoffs can quietly corrupt labels.
Choose the right inference pattern for your workflows
Where inference runs determines latency, resilience, and cost. Pick the pattern deliberately.
Common patterns and when they fit
- Synchronous inference (in-request)
- Best for decisions that must happen immediately and can tolerate strict timeouts
- Best for decisions that must happen immediately and can tolerate strict timeouts
- Asynchronous inference (queue + persistence)
- Best for routing, prioritization, enrichment, batch scoring, and non-blocking UX
- Best for routing, prioritization, enrichment, batch scoring, and non-blocking UX
- Edge inference (device or gateway)
- Best for low-latency, privacy-sensitive, or offline environments
- Best for low-latency, privacy-sensitive, or offline environments
Non-negotiable runtime protections
- Timeouts and circuit breakers for model calls
- Graceful degradation when inference is unavailable
- Idempotent decision handling so retries do not double-apply actions
- Fallback path to rules or human review
Separate feature computation from model serving
Feature chaos is one of the fastest ways to lose reproducibility. Even without a full feature store, you need feature discipline.
Minimum viable feature layer
- Versioned feature definitions (what a feature means and how it is computed)
- Online/offline parity so training and serving compute the same values
- Dataset snapshots tied to feature versions
- Backtesting support against historical event streams
Outcome: model iteration becomes engineering work, not archaeology.
Observability that understands ML failure modes
Classic monitoring checks uptime and error rates. AI systems need signals that reflect data and decision quality.
What to monitor in production
- Input drift: missing fields, distribution shifts, new categories
- Output drift: score distribution shifts, confidence collapse, anomaly spikes
- Fallback rate: how often rules or manual review are triggered
- Override rate: human corrections per segment and per reason
- Outcome metrics: tied to business events, delayed where necessary
If these metrics are not in place, performance can degrade for weeks before anyone notices.
Governance as system controls, not documents
For many teams, governance becomes a PDF checklist. AI-ready architecture turns governance into enforceable controls.
Controls that prevent operational risk
- Access control for training datasets, labels, and feature definitions
- Audit logs for dataset changes, threshold updates, and routing rules
- PII minimization and privacy-safe feature design
- Retention and deletion workflows that also affect derived artifacts
- Approval workflow for production threshold changes
What to change before ML and what you get back
| Readiness area | Typical symptom | What to change | Deliverable you can ship |
| Identity and entity mapping | Duplicates, inconsistent joins, missing history | Canonical IDs, mapping tables, merge rules | Stable training sets and reliable attribution |
| Event trail and outcomes | No way to measure real impact | Decision events, outcome events, override events | Online evaluation and feedback loop |
| Data contracts | Pipeline breaks on “small” upstream changes | Schema contracts, validation, versioning | Predictable pipelines and fewer regressions |
| Inference integration | Latency spikes or random downtime breaks UX | Async patterns, timeouts, circuit breakers | Resilient product behavior |
| Feature discipline | Offline results cannot be reproduced | Versioned feature definitions, snapshots | Repeatable training and safer releases |
| Observability | Performance silently degrades | Drift, fallback rate, overrides, outcomes | Early detection and controlled iteration |
| Governance | Changes happen without accountability | ACLs, audit logs, approvals | Compliance that works in practice |
A practical implementation roadmap
Stage 1: Instrumentation and contracts
- Define the decision contract
- Fix identifiers and mapping rules
- Capture decision events and outcome events
- Add validation for critical schemas
Deliverable: stable data foundation and measurable outcomes.
Stage 2: Safe integration of baseline ML
- Choose inference pattern (sync vs async)
- Implement timeouts, fallback, idempotency
- Deploy a baseline model with clear thresholds
- Start tracking drift, fallback, and overrides
Deliverable: a production ML loop that does not break operations.
Stage 3: Iteration and scale
- Introduce versioned features and dataset snapshots
- Add canary releases and A/B testing tied to outcomes
- Improve labeling and feedback collection
- Automate retraining triggers with guardrails
Deliverable: repeatable improvements with controlled risk.
FAQs
What is the most common blocker before ML?
Missing outcome data. Teams can log actions, but cannot link decisions to what happened later, so they cannot measure impact or create reliable labels.
Do we need a feature store from day one?
Not necessarily. You need feature versioning and reproducibility first. A feature store becomes useful when multiple models and teams reuse features at scale.
Should ML replace business rules?
No. Use rules as guardrails and ML for ranking, scoring, prioritization, or routing. Keep a fallback path for low confidence and edge cases.
How do we keep ML from breaking the product when inference fails?
Use timeouts, circuit breakers, async workflows where possible, and graceful degradation. The system must remain stable even when the model is wrong or unavailable.
What should we measure in production if labels are delayed?
Track proxy metrics (fallback rate, override rate, score distribution) and connect them to delayed outcomes when they arrive. This gives early signals without pretending you have instant truth.
How long does “AI readiness” typically take?
If the core data model is reasonable, teams can implement the foundational instrumentation and contracts in a few sprints. The exact timeline depends on how fragmented identifiers and outcomes are.
Turn this into an internal audit and a delivery plan
If you want to operationalize this article, the fastest next step is an AI-readiness audit with three outputs:
- A decision contract for your first ML use case
- A data and event instrumentation plan with exact events and schemas
- An integration blueprint (sync vs async inference, fallbacks, monitoring)
This work is also where Warehouse Layout Design projects benefit from AI-readiness principles, because optimization depends on consistent event signals, clean entity models, and measurable outcomes.
Have a project in mind?
Let's chat
Your request has been accepted!
In the near future, our manager will contact you.
Have a project to discuss?

Have a partnership in mind?
