How to Prioritize an AI Backlog in Multi-Product Companies
Why prioritization breaks in multi-product AI roadmaps
In Retail App Development, AI rarely behaves like a normal feature request. A “simple” personalization idea can quietly require shared identity, clean event streams, new data permissions, security review, platform latency work, and a real fallback plan for when inference is slow or wrong.
That’s why AI backlog prioritization is not about ranking ideas. It’s about allocating shared capacity across data, platform, security, and operations. If those constraints stay implicit, teams ship prototypes that look fine in demos but fail under production traffic.
Prioritize AI initiatives, not features
Treat the unit of work as an AI initiative, not a feature ticket.
An AI initiative is a bounded scope that includes:
- Decision and workflow: what decision changes, where it happens, who is affected
- Data path: sources, permissions, quality, freshness, missingness, retention
- Integration point: where inference runs, latency expectations, failure handling
- Evaluation plan: baseline, success thresholds, measurement method, sampling
- Operating plan: monitoring, ownership, incident response, change control
This avoids a common failure mode: a prototype that “works” in isolation but becomes unreliable and expensive when it meets real workflows and real accountability.
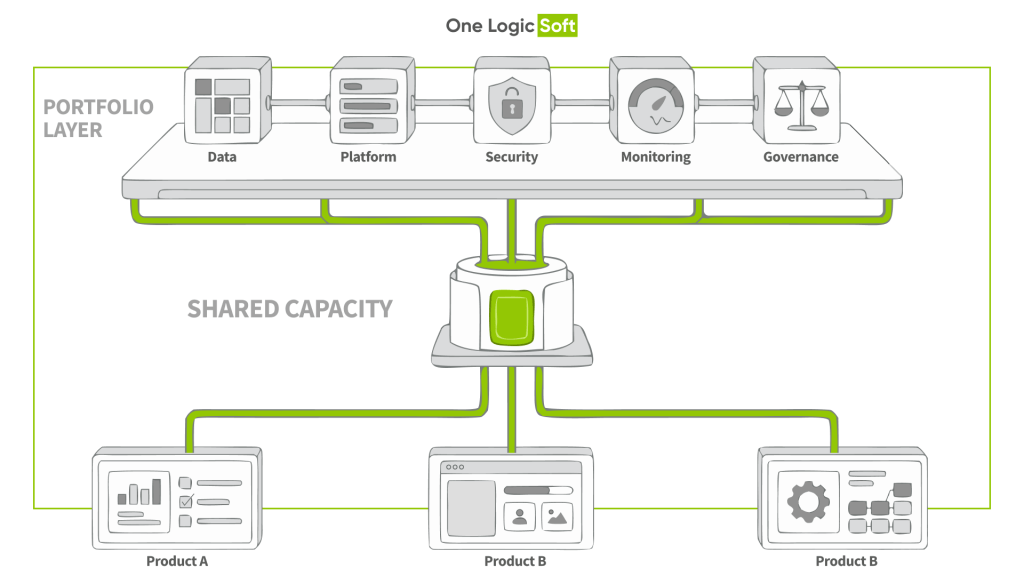
Use a two-layer backlog so teams stop fighting one list
Portfolio layer
The portfolio layer answers: what gets shared capacity next?
It contains:
- Cross-product AI initiatives
- Shared capabilities (event standards, evaluation harness, serving templates)
- Data access and governance enablers
- Reliability work (monitoring, drift checks, runbooks)
- Compliance and security remediation tied to delivery
A portfolio view turns repeated needs into shared enablers, so product teams stop rebuilding the same foundations in parallel.
Product layer
The product layer answers: what each product team ships inside allocated capacity.
Product teams still own roadmaps, but plan inside explicit constraints:
- Platform dependency windows
- Data team throughput and pipeline timelines
- Security and governance review capacity
- Release sequencing across products
In Logistics App Development, this separation matters a lot. Route planning, ETA accuracy, warehouse scanning events, and delivery exceptions often share the same data contracts and the same reliability requirements. Portfolio-level groundwork like event consistency and safe fallbacks tends to unlock multiple workflows at once.
The intake gate that keeps the backlog sane
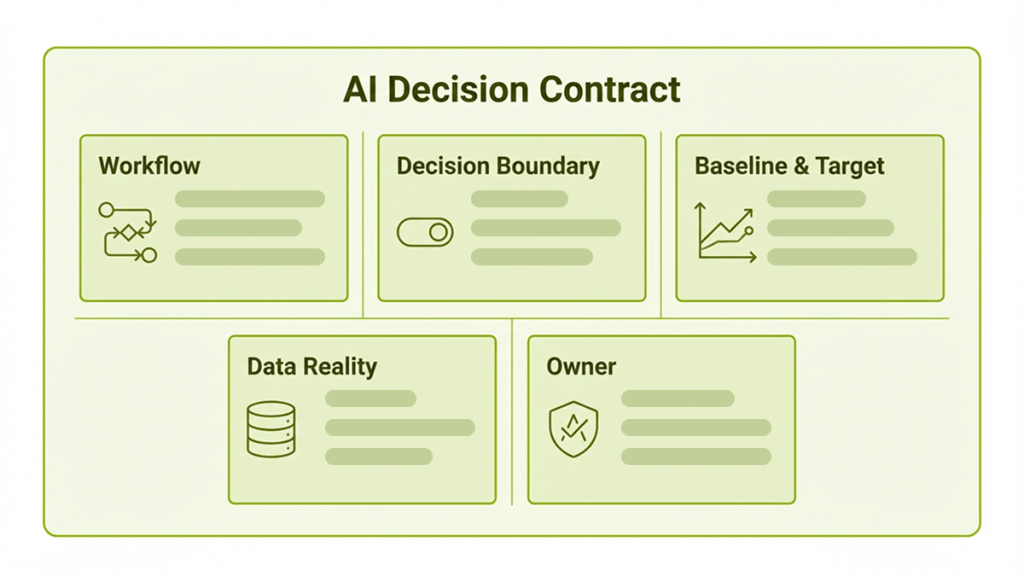
Before anything competes for build capacity, require a one-page decision contract. If it’s incomplete, the item stays in discovery.
One-page decision contract
User and workflow
- Who uses it?
- What step changes after the output appears?
Decision boundary
- When does the system trust the output?
- When does it fall back to rules or human review?
Baseline and success metric
- Current: time, cost, error rate, conversion, risk events
- Target: numeric threshold for a pilot
Data reality
- Sources, availability, permissions
- Freshness, missingness, known quality risks
Owner
- Named individual or team accountable after launch
If one field is missing, the initiative is not schedulable. Keep it in discovery until it becomes planable.
Score work with AI-specific dimensions
Classic prioritization often misses the costs that dominate AI delivery: data readiness, integration friction, operational load, and review throughput. A scorecard makes these tradeoffs visible across products.
AI backlog prioritization scorecard
| Dimension | What you are checking | Evidence you need | Score (1-5) |
| Economic impact | revenue lift, cost reduction, risk reduction | baseline metric, target, unit economics | |
| Time criticality | whether delay reduces value | deadline, seasonality, external dependency | |
| Confidence in value | strength of evidence | experiment results, user research, historical trend | |
| Data readiness | access, quality, permissions, freshness | sample profile, access confirmed | |
| Integration effort | APIs, latency, failure handling | integration notes, fallback design | |
| Operability | monitoring, drift checks, runbooks | owner named, dashboards outline, on-call path | |
| Risk and compliance | privacy, security, audit needs | risk notes, mitigation plan | |
| Cross-product leverage | reuse potential across products | reuse map, adoption plan | |
| Job size | effort and calendar time | sizing estimate, critical path |
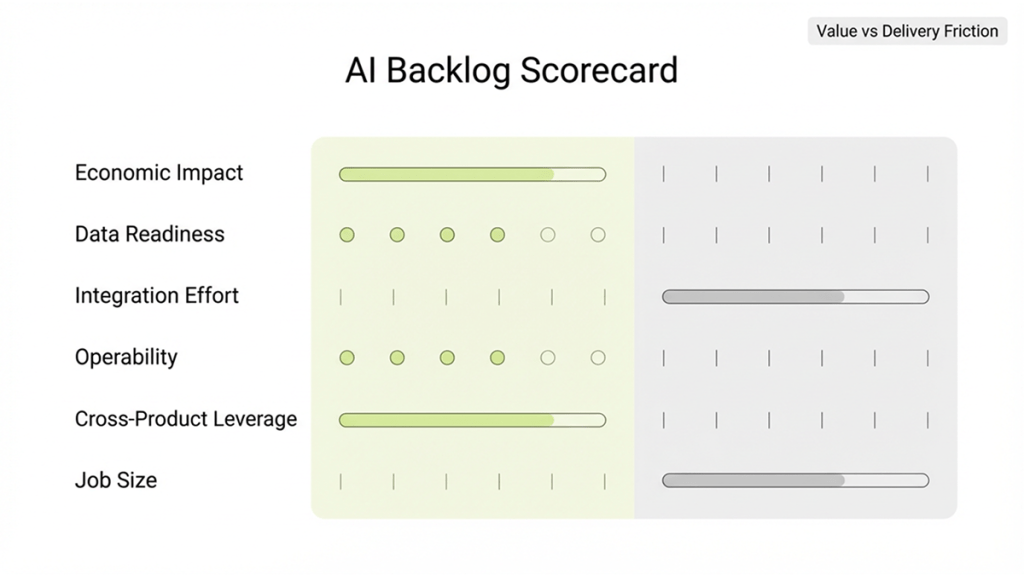
How to interpret the scores
- Build a value signal from:
- Economic impact + Time criticality + Confidence in value
- Economic impact + Time criticality + Confidence in value
- Build a delivery friction signal from:
- Data readiness + Integration effort + Operability + Risk and compliance
- Data readiness + Integration effort + Operability + Risk and compliance
- Treat Cross-product leverage as a multiplier:
- High reuse can justify funding even when one product’s local value is moderate
- High reuse can justify funding even when one product’s local value is moderate
- Use Job size to keep sequencing honest:
- Smaller, high-confidence initiatives can validate foundations and unblock bigger bets
- Smaller, high-confidence initiatives can validate foundations and unblock bigger bets
The goal is consistency, not perfect math. You want a repeatable way to expose hidden constraints and force explicit choices.
Solid facts teams can verify internally
- If data access is not approved, the initiative is not schedulable. It should not receive dates or sprint commitments.
- A model without a baseline metric cannot be “improved” in business terms. Without a current number, you cannot prove lift, savings, or risk reduction.
- Most delivery delays come from dependencies rather than modeling. Instrumentation gaps, integration work, and review throughput often dominate timelines.
- If nobody owns incidents, you accumulate operational risk debt. AI introduces failure modes that need monitoring, rollback paths, and accountability.
- Shared foundations reduce duplicated work. Common telemetry, evaluation patterns, and serving templates lower repeated integration cost across products.
Common questions and answers
What is the minimum info required to prioritize an AI initiative?
You need:
- A workflow decision that changes after the output appears
- A baseline metric and a numeric pilot threshold
- Confirmed data sources with access and freshness
- A named owner responsible for monitoring and incidents
If any one is missing, keep it in discovery.
Why is “model accuracy” a weak prioritization metric?
Because accuracy does not guarantee workflow impact. Accuracy can rise while the business metric stays flat if:
- Output arrives too late to be acted on
- Users do not trust the output
- Decision boundaries are unclear
- Integration lacks fallbacks and gets disabled under real conditions
Prioritize the workflow outcome, then measure model performance against that outcome.
How do we prevent teams from fighting over one backlog?
Use two layers:
- Portfolio layer decides what consumes shared capacity
- Product layer ships inside allocated constraints
This makes shared enablers and governance work explicit, instead of becoming invisible blockers.
What do we do with “cool ideas” that have unclear value?
Do not rank them against delivery-ready work. Put them into a time-boxed discovery track that outputs:
- A completed decision contract
- A baseline measurement plan
- A small test that can prove or kill the idea quickly
If it stays vague, it stays out.
How do we decide between a product-specific win and a shared platform enabler?
Use the scorecard and apply the leverage multiplier. A shared enabler often wins when it:
- Removes recurring integration work across products
- Improves measurement quality for multiple initiatives
- Reduces incident rates and operational load across the portfolio
What are the fastest “no” rules to protect shared capacity?
Stop or pause when:
- No measurable success metric exists
- Data access is blocked or unclear
- Operational ownership is missing
- Integration requires platform work with no staffing window
- The plan depends on future data that is not scheduled
What to do next
If you manage Hybrid App Development across multiple products, AI stays stable after launch when you standardize telemetry, reuse serving patterns, and assign clear operational ownership.
If you share your initiatives as bullet points, I’ll return:
- A ranked shortlist of what to fund next
- Dependency notes across data, platform, and security
- A 30-day sequencing plan for discovery, pilots, and shared enablers
Have a project in mind?
Let's chat
Your request has been accepted!
In the near future, our manager will contact you.
Have a project to discuss?

Have a partnership in mind?
