AI-Ready Data Architecture Before Adding AI to Business Software

A company decides to add AI to an existing business system.
The idea sounds useful from the start. An AI assistant could summarize customer requests, classify documents, prepare product updates, support dispatchers, detect stock issues, and show managers where daily work is slowing down.
Then the team checks the real system.
Customer data lives in the CRM, ERP, support desk, and spreadsheets. Product attributes differ between the storefront and the internal catalog. Stock data depends on warehouse sync. Shipment updates arrive through APIs, emails, driver notes, and partner portals. Some user roles were created years ago and never reviewed. Order status shows the final state, but not the chain of events that led to it.
This is where AI stops being a model choice and becomes a software architecture question.
IBM describes AI-ready data as high-quality, accessible, and trusted information for AI training and AI initiatives. Gartner predicts that through 2026, organizations will abandon 60% of AI projects that are not supported by AI-ready data. McKinsey’s research on agentic AI at scale points to the same barrier: eight in ten companies cite data limitations as a roadblock to scaling agentic AI.
For business teams, the key question is simple: can the current system give AI trusted, current, permission-safe data for one useful workflow?
What AI-Ready Data Architecture Means
AI-ready data architecture is the structure that lets AI work with business data without breaking process logic, access rules, or operational trust.
It defines where data comes from, which system owns the final value, who can access each field, how business events are tracked, and what happens when integrations fail.
This work connects directly with custom software development, project planning, and QA in product development. AI may sit on top of the product, but its value depends on the layer beneath it: data ownership, APIs, permissions, logs, fallbacks, and human approval points.
A simple assistant can answer from one document. A production AI workflow has to work inside CRM, ERP, OMS, WMS, TMS, POS, support tools, reporting systems, documents, and partner APIs.
Why Legacy Data Breaks AI Value
Legacy data creates risk when the business has changed, but the data model stayed the same.
A retail company may add marketplaces, loyalty rules, B2B pricing, regional catalogs, POS logic, returns, promotions, and warehouse sync. A logistics company may add new carriers, delivery zones, route planning tools, proof-of-delivery documents, partner APIs, and exception workflows.
The software may still run. AI will see the weak points.
Common blockers include:
- Duplicate records across CRM, ERP, storefronts, support tools, and spreadsheets
- Unclear source of truth for customers, products, stock, prices, shipments, and refunds
- Old permission rules that give users more access than their current role needs
- Missing event history when the system stores only the final status
- Manual workarounds hidden in comments, emails, exports, and private spreadsheets
The fix is not a large abstract cleanup program. The stronger move is to choose one AI workflow, repair the data path behind it, test it with real edge cases, then expand.
Start With One Workflow
AI readiness starts with a narrow business workflow.
A weak goal sounds like this: “We want AI in operations.”
A stronger goal sounds like this: “We want AI to classify logistics exceptions by shipment status, customer SLA, delay reason, and dispatcher owner, then prepare a review queue.”
This type of framing matches the logic in AI Workflow Automation: How to Decide What Should Be Automated First. One Logic Soft describes AI workflow automation as a planning task that starts with the business goal, workflow, systems, data sources, release scope, QA logic, and post-launch ownership.
Good first use cases usually sit close to daily work:
- Support ticket summary for faster triage
- Product attribute cleanup for catalog teams
- Stock mismatch review for retail operations
- Invoice field extraction for finance teams
- Dispatcher briefing for logistics teams
- Customer update draft for support teams
- Exception detection for managers and operators
The first release is safer when AI drafts, classifies, flags, recommends, or summarizes. Actions that affect pricing, refunds, customer promises, stock allocation, account access, or compliance need human review until the workflow proves stable.
Define the Source of Truth
AI needs to know which system owns each business object.
In retail, this may include customer profiles, products, SKUs, price lists, stock balances, promotions, orders, refunds, loyalty accounts, stores, and warehouses. In logistics, it may include shipments, routes, carriers, drivers, vehicles, delivery zones, proof-of-delivery files, customer SLAs, and exceptions.
If the ERP, CRM, admin panel, and spreadsheet all update the same object, AI has no stable answer. It can retrieve data, but it cannot judge which value is trusted.
This is one reason integration planning matters. One Logic Soft’s article on software integration timeline risks explains how integration work can break at field mapping, sync direction, API behavior, ownership, and hidden business rules. AI adds pressure to the same weak points.
Before AI reads business data, the team needs clear answers:
- Which system owns the record?
- Which systems can update it?
- What happens when sync fails?
- Which timestamp wins during a conflict?
- Who approves conflicting data?
- Which data should AI ignore?
These answers turn AI from a loose assistant into a controlled software feature.
Clean Master Data Around the AI Use Case
Master data gives AI stable business meaning.
A model can process language, but it cannot determine which customer ID, SKU, warehouse, route, contract, carrier, or price tier is correct when multiple versions exist across systems.
The cleanup should follow the workflow. If the first AI release supports product managers, product data becomes the priority. If it supports dispatchers, shipment, route, warehouse, and exception data become the priority. If it supports customer service, account history and permissions come first.
This approach keeps the work practical and prevents AI readiness from turning into an endless data-cleaning project.
Rework Permissions for AI Retrieval
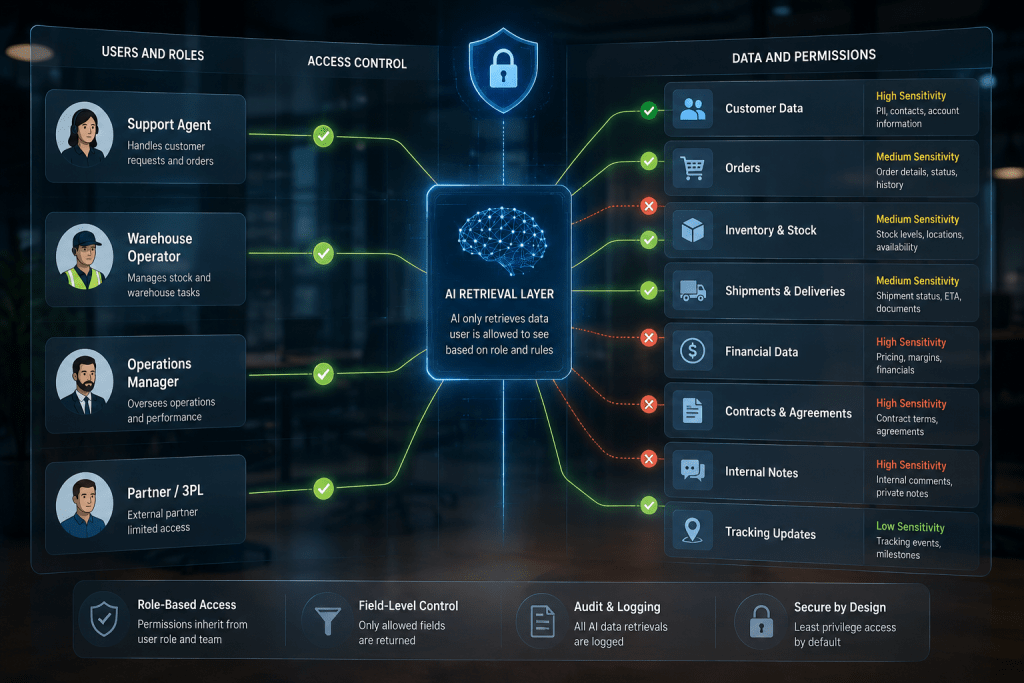
AI permissions need more control than normal screen permissions.
A user opens one order, one account, one report. AI can retrieve data across many systems in one answer. It may combine support notes, order history, product data, internal comments, delivery status, and documents.
That creates a new access question: what can AI retrieve on behalf of this user?
A support agent should not receive margin data through an AI answer. A warehouse operator should not see contract terms. A partner user should not access internal exception notes. A manager may see a full summary, but a frontline user may need a limited version.
This connects with From AI Pilot to Production. Production AI needs API limits, data boundaries, logs, fallback flows, and clear ownership. The assistant should inherit user access rules, respect field restrictions, log retrieved records, and keep sensitive actions behind approval.
Add Event Tracking Before AI Analysis
AI cannot reason from final status alone.
A shipment marked “delayed” is not enough. The system needs the timeline: shipment created, warehouse handoff started, vehicle assigned, carrier update received, ETA changed, exception opened, dispatcher note added, customer notified, approval given, delivery completed.
The same applies to retail. An order marked “refunded” does not show payment authorization, return request, stock check, manager approval, warehouse receipt, and refund completion.
Event tracking turns business activity into usable context. It lets AI detect repeated bottlenecks, late updates, failed sync, manual overrides, approval patterns, and exception causes.
This matters in complex logistics systems. In the UVK order management system case, One Logic Soft describes a web-based OMS for a major 3PL operator, covering order processing, transportation planning, fleet scheduling, trip tracking, inventory management, QR code generation, ERP integration, and third-party connections. A platform like that needs reliable events before AI can support dispatchers, planners, warehouse teams, and customer service.
AI-Ready Data Architecture Readiness Matrix
| Layer | What to check before AI | Strong signal |
| Workflow | One selected use case with user, data, action, and approval rule | The team can describe the first release in one workflow |
| Source systems | CRM, ERP, OMS, WMS, TMS, POS, support, documents, partner APIs | Each critical record has a trusted owner |
| Master data | Customers, products, locations, drivers, warehouses, contracts, prices | IDs, naming, statuses, and required fields are stable |
| Permissions | Human access and AI retrieval | AI sees only what the user can access |
| Events | Business timeline, not just final status | Milestones, failures, approvals, overrides, and retries are logged |
| Integrations | Data sync, errors, retries, limits, fallbacks | Failed updates are visible and owned |
| QA | Real data, weak data, restricted data, stale data | The workflow is tested beyond clean demo examples |
| Ownership | Product, engineering, QA, support | The team knows who maintains AI output quality after launch |
Mini-Case: Retail Product Data Agent
A B2B retail company wants an AI agent for product managers and dealer sales teams.
The first idea is broad. AI should answer product questions, improve catalog content, detect missing attributes, suggest related items, and prepare dealer replies.
During the architecture review, the team finds the real blocker. Product data lives across ERP, commerce platform, PIM exports, supplier files, and spreadsheets. Regional catalogs differ. Some attributes are missing. Stock depends on warehouse sync. B2B pricing depends on account tier, region, contract terms, and manager approval.
A safer first release focuses on product data quality review for selected catalog groups.
The AI workflow checks required attributes, flags inconsistent values, suggests draft descriptions, detects regional mismatches, shows source data, and sends price-sensitive cases to a manager. It does not change prices, promise stock, publish customer-facing updates, or edit approved product data without review.
This fits the platform logic shown in the Könner & Söhnen Shopify Plus commerce platform case. The case covers a unified B2C and B2B experience, partner workflows, customer-specific pricing, multi-market commerce, structured migration, and future AI-assisted regional pricing and stock allocation ideas.
For retail teams, AI becomes useful when it works from trusted product data and clear approval rules.
What One Logic Soft Reviews Before AI Development
One Logic Soft treats AI readiness as software planning, not model selection.
For an existing product, the review starts with the target workflow, current systems, data sources, user roles, integration points, business rules, and support risks. Then the team defines what needs cleanup before the first AI release: master data gaps, ownership conflicts, permission risks, missing events, weak APIs, audit needs, QA cases, and support responsibilities.
This preparation phase often includes work related to project specification and Support & Maintenance, especially when AI is being introduced into a live product with existing integrations, users, and operational dependencies.
The strongest starting point is not a large AI build. It is a focused review that answers one question: is the current software ready to give AI trusted data for a real business workflow?
FAQ
What is AI-ready data architecture?
AI-ready data architecture is the software structure that gives AI trusted, current, governed, and usable business data. It includes source systems, master data, permissions, event tracking, integrations, audit logs, and QA rules.
Is clean data enough for AI?
No. Clean data is only part of the foundation. AI needs ownership rules, access control, process history, integration behavior, and post-release monitoring.
What should be fixed first before adding AI?
Start with one workflow. Then repair the data path behind it: system ownership, master data, user permissions, event tracking, integration rules, and test cases.
Why does legacy software create AI risk?
Legacy software often contains duplicates, unclear field meanings, manual workarounds, old permissions, weak APIs, and missing event history. AI exposes these gaps when it works with live data.
Why are permissions different for AI?
AI can combine information from several systems in one answer. Retrieval has to follow the user’s role, account scope, field access, approval rights, and audit rules.
Have a project in mind?
Let's chat
Your request has been accepted!
In the near future, our manager will contact you.
Have a project to discuss?

Have a partnership in mind?
